A Deep-Dive into Fine-Tuning of Large Language Models
A Recap
In the prior blog post of the Generative AI series, titled Mastering Generative AI Interactions: A Guide to In-Context Learning and Fine-Tuning, I talked about the concepts of prompting and fine-tuning, which are ways to interact with and refine large language models. However, in my daily conversations with customers, I have found that fine-tuning needs to be better understood. That’s why I’d like to dive deeper into fine-tuning in this blog post. We will explore what it is and how it’s used so that everyone can better understand this important tool. Let’s get started!
Understanding the Concept of Fine-Tuning

The first thing to understand is that any Large Language Model, like GPT, is a pre-trained model. They are pre-trained with a lot of text data using the Transformer architecture. We discussed the training process in the blog Discover How ChatGPT is trained. While training, it learns a lot of tasks that it can perform on text, like summarization, translation, question answering, and text completion. The process of completion of a specific task is encoded parameters. A parameter in the GPT model refers to the values assigned to the neural network’s weights during the training process. These weights are adjusted as the model learns from the training data, allowing it to make better predictions on new data: the more parameters, the better the model’s ability to perform a specific task. Large Language Models like GPT-3 have 175 billion parameters, BARD has 1.6 billion parameters, and PaLM has 2.7 billion.
Fine-Tuning Under the Hood
Let us now discuss how the process of fine-tuning works under the hood. Fine-tuning LLMs (just super smart neural networks) is a way to optimize the model’s weights and biases. This optimization helps to minimize errors on new tasks or datasets. Check out the diagram on how this process breaks down below:

Let us discuss the process in detail.
- Starting Point: First, you start with a pre-trained model. That means it’s already got some weight and bias from its original training on a big corpus of data. This training gives it a solid foundation of knowledge to work with
- Backpropagation: As with any neural network training, the core concept remains the same. You feed the model input data; it produces outputs, and you compare these outputs with the desired targets using a loss function, and then you propagate this error back through the model to adjust its weights.
- Gradient Descent: Based on the error determined by the loss function, the model uses gradient descent (or its variants like Adam, RMSProp, etc.) to find the direction and magnitude to adjust the weights and biases. The idea is to nudge the weights and biases in a direction that reduces the error.
- Learning Rate: One crucial hyperparameter in fine-tuning is the learning rate. Typically, a lower learning rate than usual is used in fine-tuning. This calibration ensures that the model does not make drastic changes to its weights and retains much of its pre-trained knowledge while still adapting to the nuances of the new dataset.
- Regularization: To prevent overfitting on the new dataset (especially if it’s smaller than the original training dataset), techniques like dropout, weight decay, or early stopping might be used.
In contrast to few-shot learning, where the model is provided with only a few examples as input prompts to guide its output without explicit fine-tuning, fine-tuning involves additional training on a new dataset, which updates the model’s weights and biases.
Scenarios for Fine-Tuning
Fine-tuning is not the norm, but there are some use cases where fine-tuning the underlying model can yield better output and cost less. Here are a few scenarios and a table that explains when to consider fine-tuning:

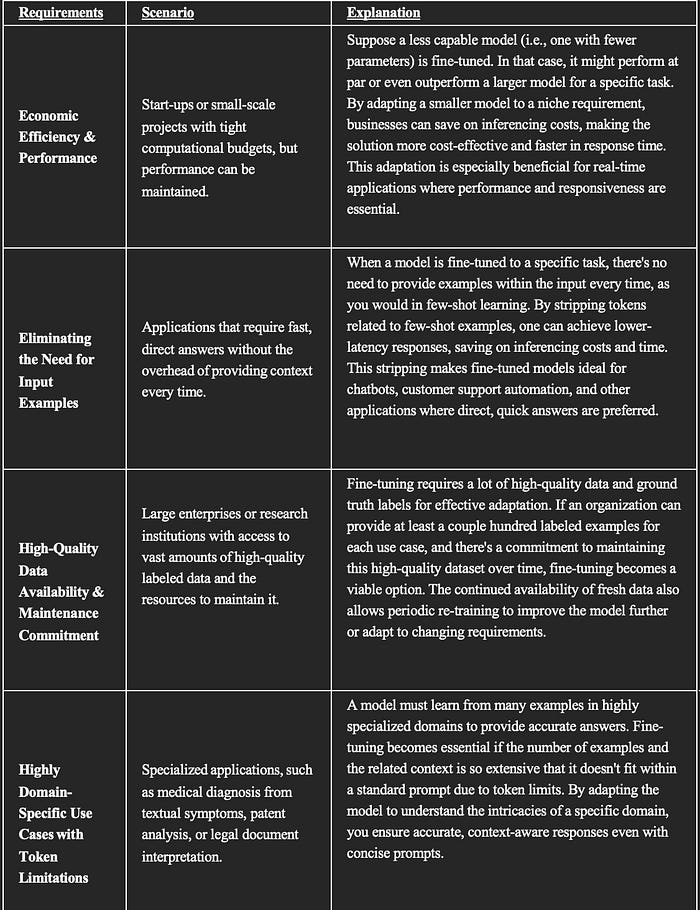
Guidance on how to approach Fine-Tuning
Fine-tuning large language models makes a difference in improving their performance for specific tasks. But it’s essential to plan and execute the process carefully. Here’s a friendly step-by-step guide to get you started:
1. Engineering Your Prompts with Foundation Models:
Approach: Before jumping into fine-tuning, try to achieve satisfactory performance by simply engineering the prompt you provide to the foundation model.
Steps:
- Experimentation: Create multiple versions of prompts for your task. For example, if you’re building a sentiment analysis tool, instead of just asking, “What’s the sentiment?”, you could prompt the model with “On a scale from 1- 10, where one is extremely negative and ten is extremely positive, how would you rate the sentiment of this text?”
- Evaluation: Test these prompts with varied inputs to determine which gives the most consistent and accurate results.
- Optimization: Keep iterating on your prompt based on the model’s responses until you achieve the best outcome.
2. Creating Dynamic Prompts using Similarity Search:
Approach: When your content base is vast, and static prompts might not cover the granularity of the information, dynamically generating prompts can be effective.
Steps:
- Identify Core Content: Have a well-indexed repository of your content.
- Search Mechanism: Implement a similarity search (like cosine similarity) to identify the most relevant content pieces for a given query.
- Dynamic Prompt Formation: Use the identified content to form a tailored prompt for the foundation model, ensuring that the most pertinent information is provided.
3. Comparative Analysis- Advanced vs. Less Capable Models:
Approach: Before investing resources into fine-tuning, it’s valuable to evaluate if a less capable model can meet your requirements compared to more advanced ones.
Steps:
- Foundation Model Evaluation: Use prompt engineering on advanced models and assess their performance, latency, and cost.
- Fine-tuning Lesser Models: Take a less capable model, fine-tune it for your task, and compare its metrics with the advanced models.
- Decision Point: Based on the comparative analysis, decide whether the benefits of fine-tuning a lesser model (like reduced costs) outweigh the advantages of using a more advanced foundation model.
4. Fine-Tuning with Quality Data:
Approach: If you decide to go down the fine-tuning route, the quality of your data becomes paramount. A model is only as good as the data it’s trained on.
Steps:
- Data Curation: Ensure you’re using the highest quality dataset available. This surety means clean, well-labeled, and diverse data that accurately represents the problem space.
- Monitor Validation Metrics: Regularly check metrics on your validation set during the fine-tuning process. This check will give you insights into how well the model is adapting.
- Regularization and Parameter Adjustment: If you notice signs of overfitting (like high training accuracy but low validation accuracy), consider techniques like dropout, weight decay, or adjusting the learning rate. Similarly, if there’s underfitting, the model might need more epochs, a varied learning rate, or even architectural changes.
Conclusion
In conclusion, while LLMs offer robust capabilities out-of-the-box, there are scenarios where their utility can be amplified manifold through fine-tuning. Whether it’s for economic efficiency, direct task-specific responses, leveraging high-quality data, or handling domain-specific challenges, fine-tuning provides a pathway to customize and enhance the capabilities of LLMs to meet specific needs. Though Fine-tuning is a potent mechanism, it’s also resource-intensive. A well-planned approach, starting with prompt engineering and culminating in a carefully monitored fine-tuning process, can help ensure optimal results with judicious use of resources.
